





















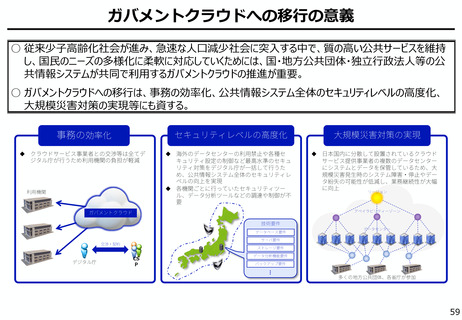
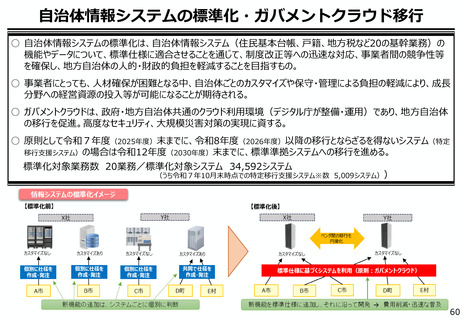
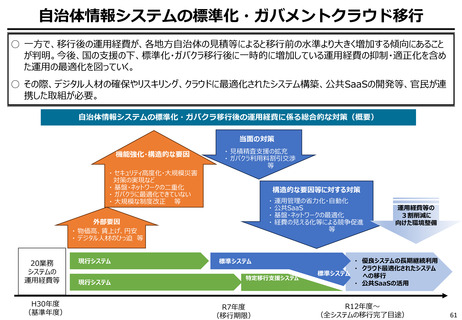
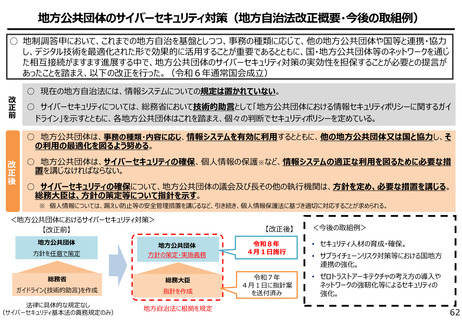
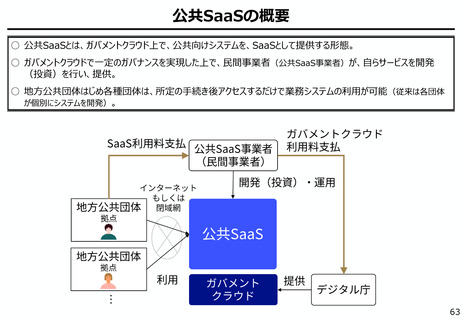






よむ、つかう、まなぶ。
資料3-2:事務局参考資料 (7 ページ)
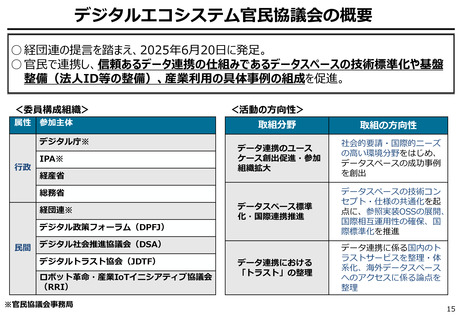
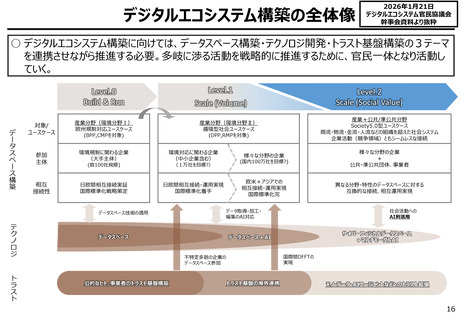
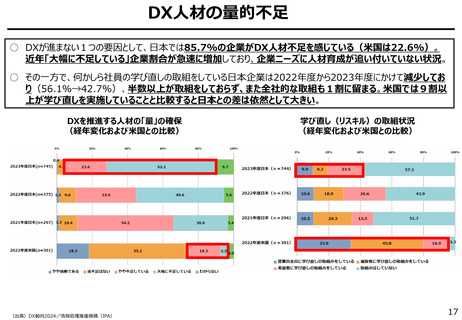
出典
| 公開元URL | https://www.digital.go.jp/councils/digital-cybersecurity/b37edb39-2a1c-4a1f-8c5e-431fcc299cd5 |
| 出典情報 | デジタル・サイバーセキュリティワーキンググループ(第1回 2/3)《デジタル庁》 |
ページ画像
ダウンロードした画像を利用する際は「出典情報」を明記してください。
低解像度画像をダウンロード
プレーンテキスト
資料テキストはコンピュータによる自動処理で生成されており、完全に資料と一致しない場合があります。
テキストをコピーしてご利用いただく際は資料と付け合わせてご確認ください。
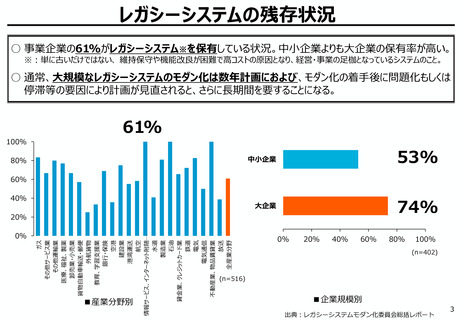
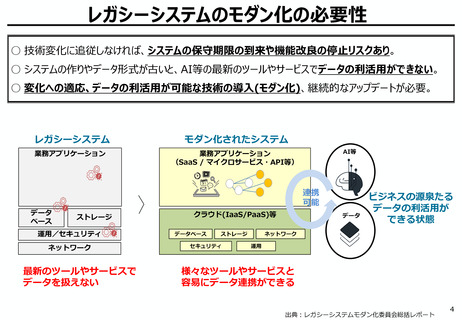
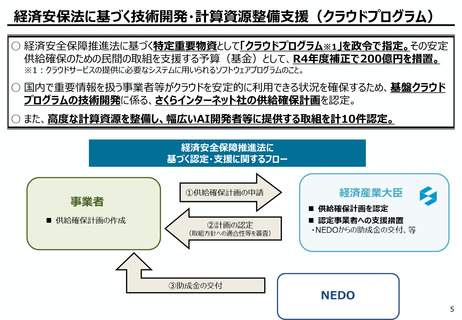
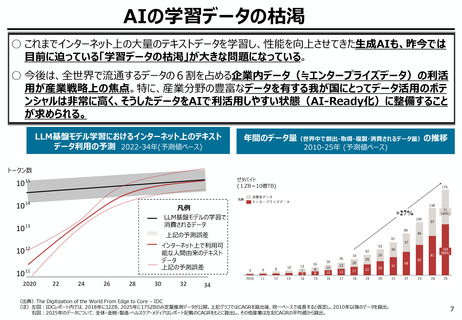
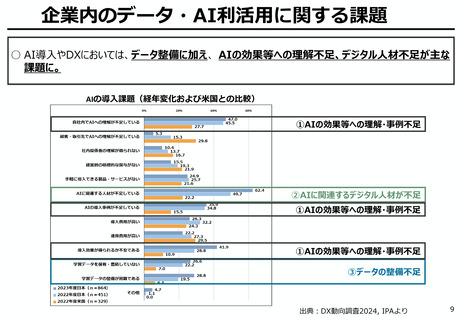
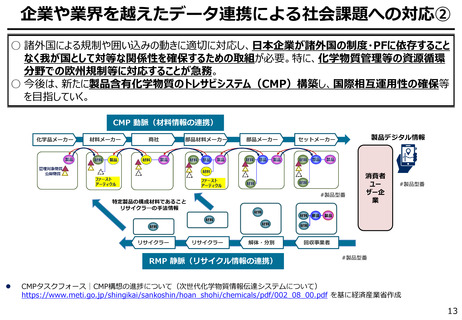
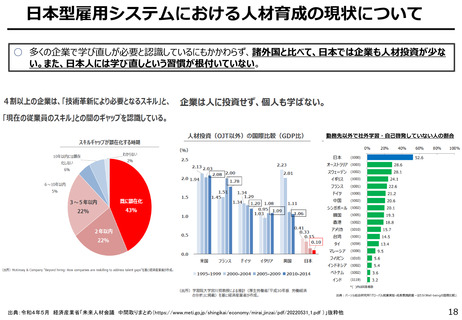
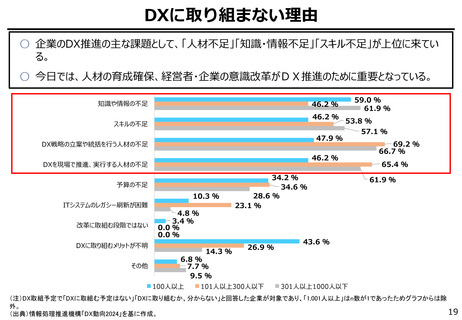
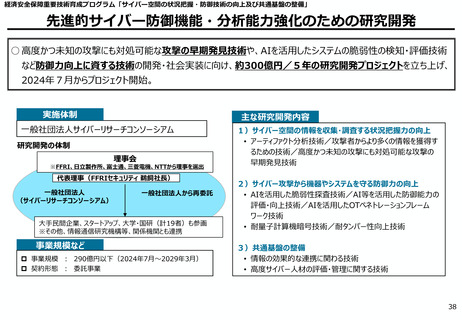
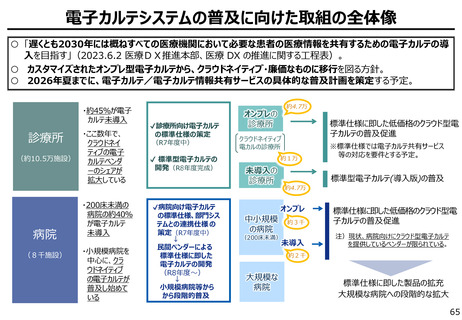
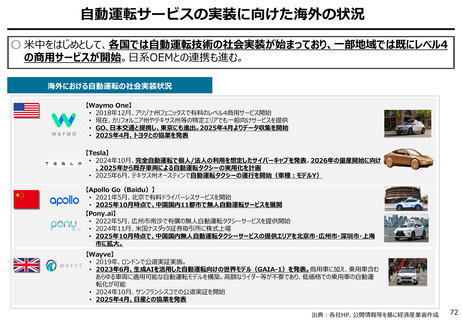
AIの学習データの枯渇
○ これまでインターネット上の大量のテキストデータを学習し、性能を向上させてきた生成AIも、昨今では
目前に迫っている「学習データの枯渇」が大きな問題になっている。
○ 今後は、全世界で流通するデータの6割を占める企業内データ(≒エンタープライズデータ)の利活
用が産業戦略上の焦点。特に、産業分野の豊富なデータを有する我が国にとってデータ活用のポテ
ンシャルは非常に高く、そうしたデータをAIで利活用しやすい状態(AI-Ready化)に整備すること
が求められる。
LLM基盤モデル学習におけるインターネット上のテキスト
データ利用の予測 2022-34年(予測値ベース)
年間のデータ量(世界中で創出・取得・複製・消費されるデータ量)の推移
2010-25年 (予測値ベース)
トークン数
ゼタバイト
(1ZB=10億TB)
10 15
10 14
凡例
LLM基盤モデルの学習で
消費されるデータ
10 13
上記の予測誤差
インターネット上で利用可
能な人間由来のテキスト
データ
上記の予測誤差
10 12
10 11
2020
22
24
26
28
30
32
34
(出典)The Digitization of the World From Edge to Core – IDC
(注)左図:IDCレポート内では、2018年に32ZB、2025年に175ZBのみ定量推測データが公開。上記グラフではCAGRを算出後、同一ベースで成長すると仮定し、2010年以降のデータを算出。
右図:2025年のデータについて、全体・金融・製造・ヘルスケア・メディアはレポート記載のCAGRをもとに算出し、その他産業は左記CAGRの平均値から算出。
7
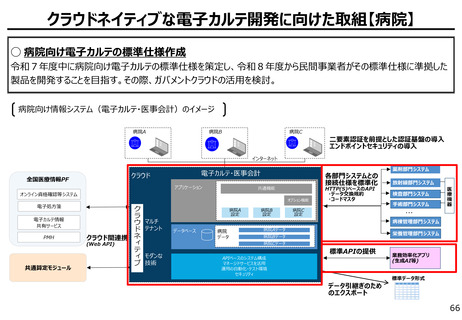
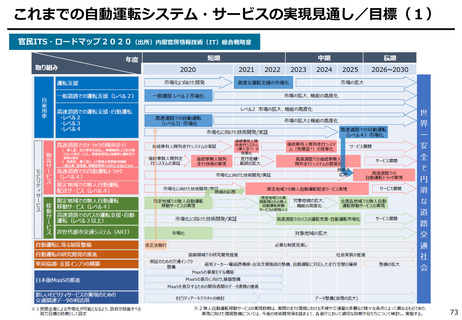
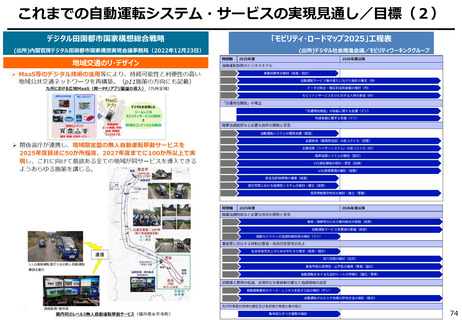
○ これまでインターネット上の大量のテキストデータを学習し、性能を向上させてきた生成AIも、昨今では
目前に迫っている「学習データの枯渇」が大きな問題になっている。
○ 今後は、全世界で流通するデータの6割を占める企業内データ(≒エンタープライズデータ)の利活
用が産業戦略上の焦点。特に、産業分野の豊富なデータを有する我が国にとってデータ活用のポテ
ンシャルは非常に高く、そうしたデータをAIで利活用しやすい状態(AI-Ready化)に整備すること
が求められる。
LLM基盤モデル学習におけるインターネット上のテキスト
データ利用の予測 2022-34年(予測値ベース)
年間のデータ量(世界中で創出・取得・複製・消費されるデータ量)の推移
2010-25年 (予測値ベース)
トークン数
ゼタバイト
(1ZB=10億TB)
10 15
10 14
凡例
LLM基盤モデルの学習で
消費されるデータ
10 13
上記の予測誤差
インターネット上で利用可
能な人間由来のテキスト
データ
上記の予測誤差
10 12
10 11
2020
22
24
26
28
30
32
34
(出典)The Digitization of the World From Edge to Core – IDC
(注)左図:IDCレポート内では、2018年に32ZB、2025年に175ZBのみ定量推測データが公開。上記グラフではCAGRを算出後、同一ベースで成長すると仮定し、2010年以降のデータを算出。
右図:2025年のデータについて、全体・金融・製造・ヘルスケア・メディアはレポート記載のCAGRをもとに算出し、その他産業は左記CAGRの平均値から算出。
7